The Eye
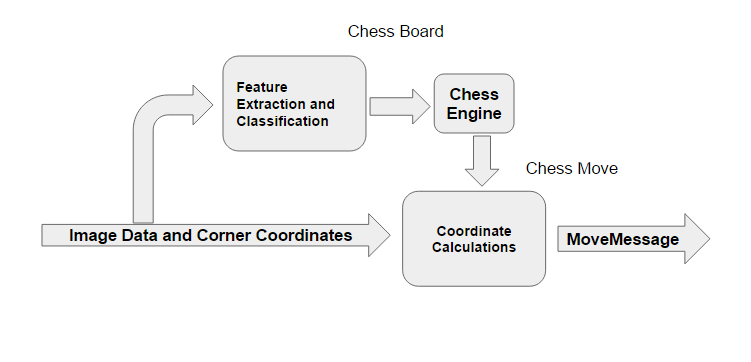
Using Baxter's hand cameras, we obtain a raw image of the board and its surroundings. It is the Eye node's job to find the chess board and map it to a 2D representation (as if taken from directly above by a camera pointing straight down) for the brain to analyze, as well as calculate the real-world coordinates of the chessboard

The first step is to find the region in the image corresponding to the chessboard. It turns out that this is pretty much a solved problem thanks to the common use of checkerboards for camera calibration; we used a built-in OpenCV library function to find the corners of the board on a scaled-down version of the camera input image, then scaled the computed corners back up to match the original input.
At this point in the pipeline, we have both the coordinates of the chessboard corners in the chessboard frame (computed from the hardcoded board square size and the known geometry of all chessboards) and the points that they map to in the input image from the hand camera. From this correspondance, we can compute a homography between the two point sets (using the RANSAC algorithm to discard outliers because some of the detected corners will actually be part of a piece rather than the board itself). We do this by using OpenCV library functions to find the RBT from the camera to the chessboard frame and compute the homography based on that RBT.

The inverse-perspective-mapped version of the chessboard image and the world-frame positions of the four outside corners are then computed. Then, all that remains is to package up the relevant data into messages and send it to the brain: the inverse-perspective chessboard image as well as the real-world coordinates of the four corners.
The main Python package used in this module is OpenCV.
The Brain
After receiving image and coordinate information from the Eye, the Brain must update its internal state, communicate with its chess engine, and then send movement coordinates to the Arm.
The first step in this process is updating the Brain's internal state. Using its previous board state and the chess engine API, the Brain generates all possible next board states. Afterwards, it takes the 2D board image and use that as evidence in order to infer the next board state. In order to figure out what the board is, we take our 2D images and split it into individual squares in order from top left to bottom right. We then featurize these squares using a Histogram of Oriented Gradients and the send these feature vectors to a Random Decision Forest that has been trained to recognize empty squares and piece colors. For each square, we get a probability distribution of the possible states: empty, contains a white piece, and contains a black piece. From there, we take each possible board and weight each board using the log sum of the probability of the board given our image. We then choose the board with the greatest weight as our board state
Once the Brain figures out what board state it is in, it can then send this board to the chess engine and query a next move. When the engine returns a move in UCI notation (i.e 'e1g1'), the brain then uses the coordinates sent from the Eye to map the squares in the move to world frame coordinates. Also returned from the engine is whether of not the move was a 'capture' and we handle that by passing that message onwards to the Arm. We then wrap these coordinates in a MoveMessage and then publish that message to the brainstem topic
The python packages used in this module are: Sklearn, Skimage, and python-chess.
The Arm
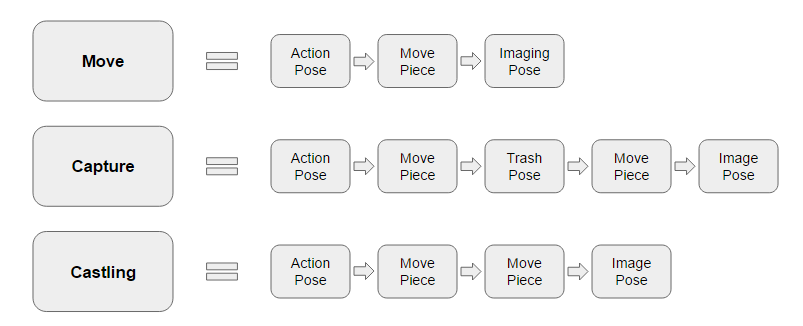
Before the game begins, we must initialize 3 of Baxter's poses or load them from a file. We then touch the gripper to the board to obtain the z-coordinate of the board. Baxter then enters a viewing state with its camera arm is a place it can see the board. Once the Arm receives a MoveMessage from the Brain, it will then parse the message for the move type. The move type can be one of capture, castle, move, or en passant. Knowing what type of move to make, Baxter then assumes its action pose, which involves moving its camera arm to a safe location and its gripper arm to the center above the board. It then performs the required action and returns its gripper hand to a safe location and moves its camera into a viewing position.
The packages we used in this module are: MoveIt!